Demystifying artificial intelligence
By: Ciopages Staff Writer
Updated on: Feb 25, 2023
Demystifying artificial intelligence for a business audience is not easy. It is fair to say that the world of business is overloaded with hype and buzz words like artificial intelligence (AI), machine learning, data science, deep learning, neural networks, natural language processing, and computer vision. Readers of this article will be aware that those technologies are changing industry landscapes. However, knowing they are important doesn’t necessarily equate to understanding what they mean.
This article attempts to cut through some of the mystique surrounding AI and machine learning, giving an overview of their state in 2020.
Demystifying Artificial Intelligence
In short, AI is the umbrella term for all the tools that we use to make computers behave in an automated and intelligent way. Programs that use AI are typically able to process vast volumes of data, imitate human thought patterns, solve problems, and self-teach with experience.
AI can be classified into two groups. General AI is the concept explained above where machines can intelligently solve problems without human input. For movie lovers out there, think of a C-3P0 or Iron Man suit, and you will get an idea of what researchers see as artificial general intelligence (AGI).
An AGI machine has cognitive abilities that allow it to understand the environment. It can apply knowledge and skills in numerous contexts and create opportunities for solving problems autonomously. AGI algorithms can process data faster than the human brain, leading to the sci-fi and fantasy idea of superior beings. In 2020, we are not close to achieving AGI yet. The AI applications in the real-world follow pre-defined rules, led by human input.
The cases of AI we see in the world today are called artificial narrow intelligence (ANI). A machine with ANI capability will operate from a pre-defined set of rules. Typical examples are a Google search knowing what results we most likely want to see, or Amazon recommending products customers will like. These examples are trained with data to create insights and make decisions.
Fields such as computer vision and natural language processing are bridging the gap between ANI and AGI, but there is still a way to go before solutions are deployed on a major scale. An example of the progress being made comes with autonomous cars. To drive without human input, an autonomous vehicle needs to see have an understanding of the environment in the same way as a human. Computing power, connectivity and algorithms are nearing a point where cars can be fully self-sufficient, but we are not there yet.
Narrow AI applications are driven by two subsets of AI known as machine learning and deep learning. The best way of explaining the link between the three is that AI is an all-encompassing term, inside of which is machine learning and then within that, we get more complex deep learning.
Demystifying artificial intelligence: What is machine learning?
Machine learning is the application of AI that takes vast amounts of data, trains itself, and makes decisions or provides insight predictively. The data used to prepare the machine is ordinarily labeled to give it a foundation for learning. For example, we might want a computer to recognize who a person is from a photo. To do so, we would load the computer with thousands of other images, some with the face of that person and others without. The images would all be labeled as either containing the face or not containing the face. When a new image is loaded into the machine, it can use the experience from previous pictures and ascertain if the person is in the photo. This is a simplistic way of explaining how Facebook is able to automatically tag photos posted to the social media platform.
The predictions that the machine makes i.e. tagging a face is what we know as AI. However, in truth, data is the driving force. All the AI solutions that people use today are powered by data. It is often the case that people confuse AI as being the device, rather than the data and algorithms that sit behind it. For example, a voice-activated device like Alexa is simply a box with speakers that connects to data. Somebody speaks to Alexa, and the command is converted to data and sent to the cloud. Once the algorithm finds a response, it sends it back via the speaker.
Voice-activated devices do a great job of appearing cognitive but, in reality, are far from it.
Types of machine learning
There are four conventional machine learning methods.
- Supervised learning
In a supervised learning model, a subset of data is taken and used to train a machine how to classify new pieces of information. For example, the engine could be loaded with records of data about people who love to watch horror movies. As soon as a new customer to the service matching those attributes joins, they either presented with or not presented horror movies as the machine classifies them. This technique is open to bias as, in theory, people classify as “not horror” will never get those movie types. Mitigating bias is a challenging task which you can read about in our other post (link here to bias article).
- Unsupervised learning
An unsupervised learning model will look to automatically classify the data without prior knowledge of human labeling. Instead of being told the possible classifications for a piece of data, the algorithm will attempt to put it into a group by itself. This technique is sometimes referred to as clustering and commonly used in marketing and retail. For example, customer purchasing behavior patterns can be hard to understand and complicated, making it difficult, if not impossible, to classify manually. The unsupervised model will take the data, map the patterns and split the information into clusters or segments.
- Semi-supervised learning
Semi-supervised learning is a mix between supervised and unsupervised learning. If there is a vast amount of data to classify, it might be impossible for a human to label all of it during the training phase. In these situations, the machine will see some labeled data and some unlabeled. If a classification exists, the machine will use it. Else, it will train itself in an unsupervised manner to specify new classifications. A human will be in the loop to verify the decision and add the new labels to the framework.
- Reinforced learning
Reinforcement learning is about giving positive and negative rewards for behaviors. The technique is especially important in robotics, where machines need to learn how to optimize their behavior after experiencing either a positive or negative result. Imagine an instance where we want to train a robot to use a television remote using machine learning. An algorithm will be written to program activities in the bot, and it will either complete it correctly or get it wrong. Perhaps it decides to throw the remote as opposed to pressing it. The robot will continue with different actions until it finds the most positive result.
Demystifying Artificial Intelligence: What is deep learning?
Deep learning is a further application of AI. It is a more evolved form of machine learning that is inspired by the processing patterns of a human brain, known as neural networks. Thy key difference between deep learning and machine learning is that while machine learning techniques take a data input and learn from it, deep learning networks will learn through their own data processing.
As we discussed in machine learning, even when methods are unsupervised, a human can still jump in and solve the problem if it is too confusing for the machine. However, deep learning algorithms will decide for themselves if a prediction is accurate.
There are innate risks with deep learning in that their conclusions are not accurate, which is why the models are accompanied by extensive testing. Until there is enough confidence that such frameworks can correctly make decisions, we won’t move to AGI solutions. However, new research and technology are getting us closer by the day.
Image recognition through computer vision is one of the leading examples of deep learning that we see today. Sensors or scanners can take images, videos, or text, and rather than simply convert them into data, understand the context around them. For example, a sensor (or collection of sensors) in a car will see a pedestrian. A machine learning model might tell the car to stop whenever it sees a pedestrian close to the road. However, a deep learning framework will enforce behaviors. It will check if there is light turning red, or whether the car is at a junction to work out the correct decision.
Deep learning makes situation-dependent decisions rather than purely rule-based ones in machine learning.
AlphaGo by Google is one of the most well-known cases of machine learning. Google trained a machine to learn the board game Go which requires a lot of intellect. Without being told what move to make, the machine learned the rules itself and began to outperform humans. If the computer had been fed rules through machine learning, this might not be hugely impressive, but the fact it learned how to win on its own is incredible.
The importance of training data
Throughout this article, we have talked about how data drives AI applications. The information used to train AI applications, known a training data, helps machines learn and make predictions. Gathering training data occurs at the very start of any AI project and is integral to the future success of the solution.
Let’s look at a voice-activated device like Alexa or Google Home. The number of people owning a smart speaker has continued to rise for the last three years. The popularity has come from them being able to quickly and accurately respond to the majority of user queries. The way they can do this is by processing massive amounts of data.
At the start, the Alexa data science team labeled millions of verbal requests and replies to ensure the device was able to fully understand its users. This was vital in allowing the team to know what type of requests consumers expected Alexa to know.
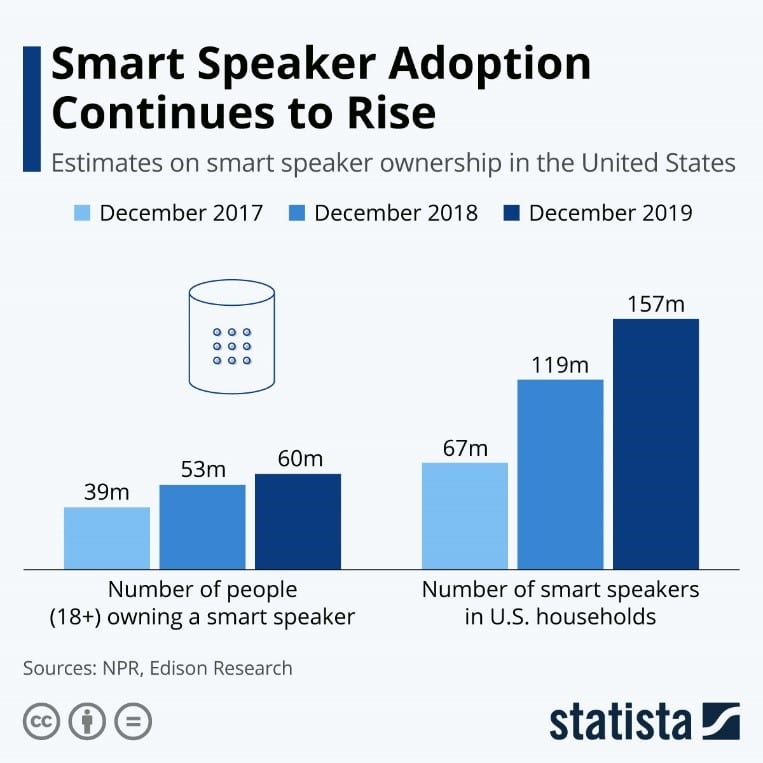 Over time, the Amazon team has been able to work with the data and move onto semi-supervised and unsupervised models. Where there have now been billions of conversations, adding a more profound complexity is fundamental to improving what voice-activated devices can do. Alexa now understands the context of some conversations and have become far better at engaging with its users.
Over time, the Amazon team has been able to work with the data and move onto semi-supervised and unsupervised models. Where there have now been billions of conversations, adding a more profound complexity is fundamental to improving what voice-activated devices can do. Alexa now understands the context of some conversations and have become far better at engaging with its users.
Had Alexa been loaded with poor quality or incomplete training data, the device would not be where it is today. People don’t want to buy a speaker system that isn’t intelligent. While small businesses are not going to compete with Amazon, the same logic still applies. Having high-quality training data can make or break an algorithm or even an entire product line.
So have we demystified artificial intelligence enough?
ANI solutions are everywhere in life, from Google searches to GPS, Alexa, smartphones, wearable devices, social media, Netflix, and Amazon, to name only a few. The immense growth of a digital ecosystem and volume of data in the world, coupled with better computing power and technology, has stimulated investment in the field. We are at a point where companies who don’t invest in ANI are falling behind the competition.
AI in healthcare and cognitive applications in financial services are evolving, slowly. And many other sectors are considering AI as a part of their business and technology landscape.
However, the goal must be to achieve AGI. Self-teaching systems that can outperform humans in tasks could be at least 30 years away with several challenges to overcome. ANI is gradually gaining public trust in machines, and that will continue to augment more advanced AGI developments.